Python 基础
本文将介绍 Python 中最基本的处理和操作。
1. 变量
在 Python 中,变量不需要声明,直接赋值即可,如下:
| Python |
|---|
| a = 'Hello, World!'
b = 100
c = True
|
2. 输出变量
可以使用多种方式输出变量内容,如下:
2.1 使用 print() 方法
print()方法直接输出变量的内容,如下:
| Python |
|---|
| a = 'Hello, World!'
print(a)
|
输出:
2.2 使用 type() 方法
type()方法返回变量的类型,可以配合print()输出,如下:
| Python |
|---|
| a = type('Hello, World!')
print(a)
|
输出:
2.3 使用 repr() 方法
repr()方法返回变量的详细信息,可以配合print()输出,如下:
| Python |
|---|
| a = repr('Hello, World!')
print(a)
|
输出:
使用 repr() 方法输出字符串带有引号,可以方便区分数字和字符串数字
2.4 输出多个值
print()可以一次输出多个变量值,方便程序关键信息的输出,如下:
| Python |
|---|
| a = repr('Hello, World!')
b = repr(100)
c = repr(True)
print(a, b, c)
|
输出:
也可以使用「标题,内容」的形式输出,方便检查每个变量的值,如下:
| Python |
|---|
| my_string = 'Hello, World!'
print('my_string:', repr(my_string))
|
输出:
| Text Only |
|---|
| my_string: 'Hello, World!'
|
3. 基本数据类型
在 Python 中,包含如下基本数据类型:
| 数据类型 |
说明 |
示例 |
None |
空值 |
a = None |
int |
整数 |
a = 100 |
float |
浮点数 |
a = 100.0 |
str |
字符串 |
a = 'Hello, World! |
bool |
布尔值 |
a = True
b = False |
在编写 Python 代码时,请勿使用数据类型名直接作为变量,如:
3.1 空值 None
None也是一种值,用来表示「什么都没有」,可以使用is或is not进行判断,如下:
| Python |
|---|
| a = None
print('a is None 结果:', a is None) # 检查是否为空
print('a is not None 结果:', a is not None) # 检查是否不为空
|
输出:
| Text Only |
|---|
| a is None 结果: True
a is not None 结果: False
|
3.2 整数 int、浮点数 float
int、float可以进行数学运算和大小判断,如下:
| Python |
|---|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18 | a = 5
b = 3
print('a + b 结果:', a + b) # 加法
print('a - b 结果:', a - b) # 减法
print('a * b 结果:', a * b) # 乘法
print('a / b 结果:', a / b) # 除法
print('a ** b 结果:', a ** b) # 指数
print('a // b 结果:', a // b) # 取整数
print('a % b 结果:', a % b) # 取余数
print('int(a / b) 结果:', int(a / b)) # 截取整数
print('round(a / b) 结果:', round(a / b)) # 四舍五入
print('a == b 结果:', a == b) # 等于
print('a != b 结果:', a != b) # 不等于
print('a > b 结果:', a > b) # 大于
print('a >= b 结果:', a >= b) # 大于等于
print('a < b 结果:', a < b) # 小于等于
print('a <= b 结果:', a <= b) # 小于等于
|
输出:
| Text Only |
|---|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15 | a + b 结果: 8
a - b 结果: 2
a * b 结果: 15
a / b 结果: 1.6666666666666667
a ** b 结果: 125
a // b 结果: 1
a % b 结果: 2
int(a / b) 结果: 1
round(a / b) 结果: 2
a == b 结果: False
a != b 结果: True
a > b 结果: True
a >= b 结果: True
a < b 结果: False
a <= b 结果: False
|
3.3 字符串 str
str可以进行字符串拼接、格式化、相等/大小判断(即判断字母排序)和包含判断,如下:
| Python |
|---|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21 | a = 'Hello, '
b = 'World!'
c = 'Hello, World'
print('a + b 结果:', a + b) # 拼接
print(f'a + b 结果: {a + b}') # 格式化
print('a > b 结果:', a > b) # 大小判断
print('a < b 结果:', a < b) # 大小判断
print('a == b 结果:', a < b) # 相等判断
print('a in c 结果:', a in c) # 包含判断
print('使用单引号表示字符串 :', '"abc"')
print('使用双引号表示字符串 :', "'abc'")
print('使用三个单引号表示字符串 :', '''abc''')
print('使用三个双引号表示字符串 :', """abc""")
print('使用三个单、双引号可以直接换行字符串:', """
123
abc
xyz
""")
print('使用转义符 \ 表示特殊符号:', '\'abc\'')
|
输出:
| Text Only |
|---|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15 | a + b 结果: Hello, World!
a > b 结果: False
a < b 结果: True
a == b 结果: True
a in c 结果: True
使用单引号表示字符串 : "abc"
使用双引号表示字符串 : 'abc'
使用三个单引号表示字符串 : abc
使用三个双引号表示字符串 : abc
使用三个单、双引号可以直接换行字符串:
123
abc
xyz
使用转义符 \ 表示特殊符号: 'abc'
|
一般来说,推荐使用格式化方式生成字符串(在 Python 中称为f-string),这样写的代码比单纯加号拼接字符串更加直观。
f-string语法结构如下:
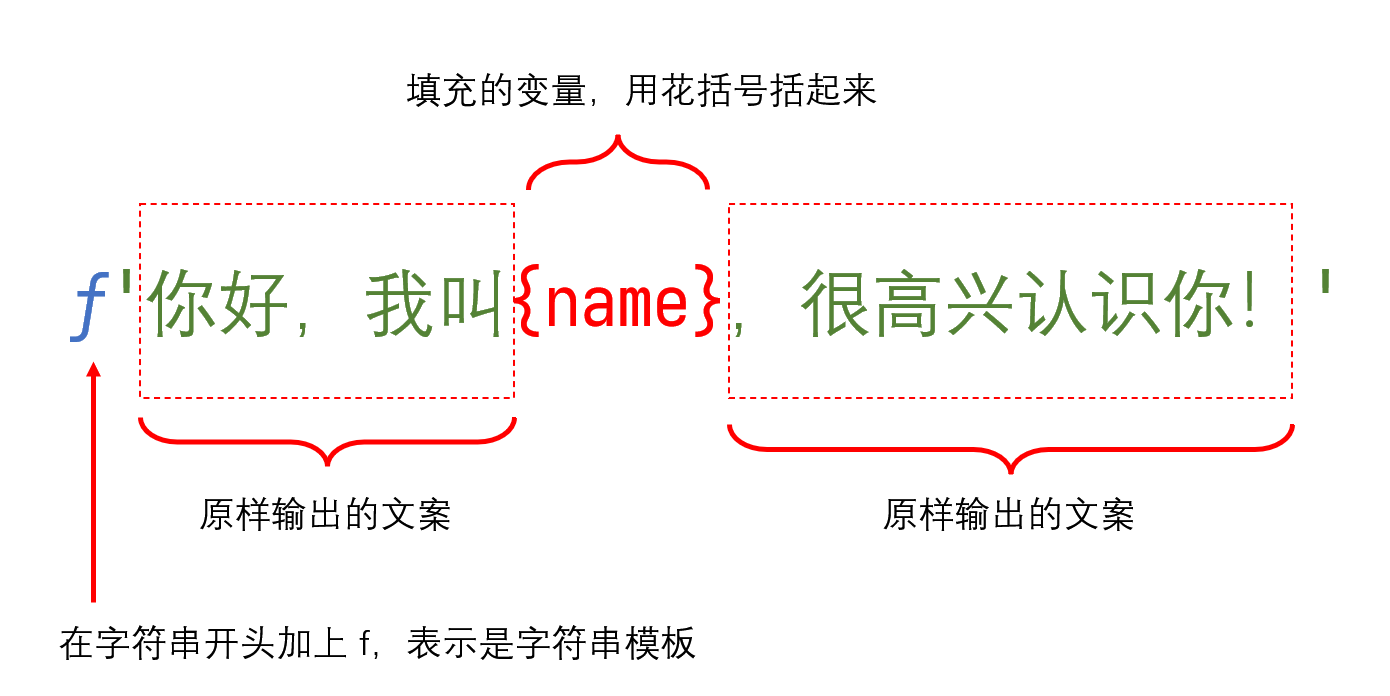
3.4 布尔值 bool
bool可以进行逻辑运算,如下:
| Python |
|---|
| t = True
f = False
print('t is True 结果:', t is True) # 判断真假
print('t is f 结果:', t is f) # 对比
print('t is not f 结果:', t is not f) # 对比
print('t and f 结果:', t and f) # 与
print('t or f 结果:', t or f) # 或
print('not t 结果:', not t) # 非
|
输出:
| Text Only |
|---|
| t is True 结果: True
t is f 结果: False
t is not f 结果: True
t and f 结果: False
t or f 结果: True
not t 结果: False
|
4. 常用数据类型
除了基本数据类型外,Python 中也自带一些非常常用的数据类型。
4.1 列表 list
列表是若干个元素的有序集合,类似其他编程语言中的数组Array。
Python 的列表中元素可以是任何类型,也不要求类型相同,如:
| Python |
|---|
| l = [] # 空列表
l = [1, 2, 3.3, True, 'Hello, World!']
|
在编写 Python 代码时,请勿使用数据类型名直接作为变量,如:
列表支持的常用操作如下:
| Python |
|---|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53 | l = [3, 2, 1]
# 添加元素
l.append(4)
print('添加元素后:', l)
# 弹出元素
x = l.pop()
print('弹出的元素:', x)
print('弹出元素后:', l)
# 合并列表
l.extend([7, 8, 9])
print('合并列表后:', l)
# 获取第一个元素(序号为 0)
print('获取第一个元素:', l[0])
# 获取最后一个元素(可指定序号为-1)
print('获取最后一个元素:', l[-1])
# 按序号范围获取元素
# 规则为按照 [开始序号:结束序号],且包含开始序号,但不包含结束序号
print('获取第 2 个至最后元素:', l[1:])
print('获取第 2 个至第 4 个元素:', l[1:4])
print('获取最后第 2 个至最后元素:', l[-2:])
# 修改元素
l[0] = 'Hello, World!'
print('修改元素后:', l)
# 循环遍历元素
print('循环遍历元素:')
for x in l:
print(' Value =', x)
# 循环遍历并附带索引号
print('循环遍历并附带索引号:')
for index, x in enumerate(l):
print(' Index =', index, ', Value =', x)
# 反转列表
l.reverse()
print('反转列表后:', l)
# 获取列表元素个数
print('获取列表元素个数:', len(l))
# 排序
# 注意:不能对数字、字符串混合列表排序
l = [4, 3, 6, 2, 7, 1]
l.sort()
print('排序后', l)
|
输出:
| Text Only |
|---|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27 | 添加元素后: [3, 2, 1, 4]
弹出的元素: 4
弹出元素后: [3, 2, 1]
合并列表后: [3, 2, 1, 7, 8, 9]
获取第一个元素: 3
获取最后一个元素: 9
获取第 2 个至最后元素: [2, 1, 7, 8, 9]
获取第 2 个至第 4 个元素: [2, 1, 7]
获取最后第 2 个至最后元素: [8, 9]
修改元素后: ['Hello, World!', 2, 1, 7, 8, 9]
循环遍历元素:
Value = Hello, World!
Value = 2
Value = 1
Value = 7
Value = 8
Value = 9
循环遍历并附带索引号:
Index = 0 , Value = Hello, World!
Index = 1 , Value = 2
Index = 2 , Value = 1
Index = 3 , Value = 7
Index = 4 , Value = 8
Index = 5 , Value = 9
反转列表后: [9, 8, 7, 1, 2, 'Hello, World!']
获取列表元素个数: 6
排序后 [1, 2, 3, 4, 6, 7]
|
4.2 元组 tuple
元组与列表类似,也是若干个元素的有序集合,但元组一经创建便无法修改。
Python 的元组中元素可以是任何类型,也不要求类型相同,如:
| Python |
|---|
| t = tuple() # 空元组
t = (1, 2, 3.3, True, 'Hello, World!')
|
在编写 Python 代码时,请勿使用数据类型名直接作为变量,如:
由于表示元组的括号可能和普通的括号混淆。因此在定义只有 1 个元素的元组时,需要额外增加一个逗号表示,如:
输出:
4.3 字典 dict
字典是若干个元素按照 Key-Value 形式组织的无序集合,类似其他编程语言中的数组Map。
Python 的字典中,Key 一般使用字符串,而 Value 可以是任何类型,也不要求类型相同,如:
| Python |
|---|
| d = {} # 空字典
d = {
'a' : 1,
'b' : 'Hello, world!'
'isOK': True,
}
|
在编写 Python 代码时,请勿使用数据类型名直接作为变量,如:
字典支持的常用操作如下:
| Python |
|---|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41 | d = {'a': 1}
# 添加/修改元素
d['b'] = 2
print('添加/修改元素后:', d)
# 弹出元素
x = d.pop('b')
print('弹出的元素:', x)
print('弹出元素后:', d)
# 合并字典
d.update({'x': 9})
print('合并列表后:', d)
# 获取元素
print('获取 Key 为 a 的元素:', d['a'])
# 获取元素,且不存在时返回 None
print('获取 Key 为 xxx 的元素,且不存在时返回 None:', d.get('xxx'))
# 获取元素,且不存在时返回默认值
print('获取 Key 为 xxx 的元素,且不存在时返回默认值:', d.get('xxx', 'Default'))
# 获取 Key 列表
print('获取 Key 列表:', list(d.keys()))
# 获取 Value 列表
print('获取 Value 列表:', list(d.values()))
# 修改元素
d['a'] = 'Hello, World!'
print('修改元素后:', d)
# 循环遍历元素
print('循环遍历元素:')
for k, v in d.items():
print(' Key =', k, ', Value =', v)
# 获取列表元素个数
print('获取列表元素个数:', len(d))
|
输出:
| Text Only |
|---|
1
2
3
4
5
6
7
8
9
10
11
12
13
14 | 添加/修改元素后: {'a': 1, 'b': 2}
弹出的元素: 2
弹出元素后: {'a': 1}
合并列表后: {'a': 1, 'x': 9}
获取 Key 为 a 的元素: 1
获取 Key 为 xxx 的元素,且不存在时返回 None: None
获取 Key 为 xxx 的元素,且不存在时返回默认值: Default
获取 Key 列表: ['a', 'x']
获取 Value 列表: [1, 9]
修改元素后: {'a': 'Hello, World!', 'x': 9}
循环遍历元素:
Key = a , Value = Hello, World!
Key = x , Value = 9
获取列表元素个数: 2
|
4.4 集合 set
字典是若干个无重复元素的无序集合。
Python 的集合中元素可以是任何类型,也不要求类型相同,如:
| Python |
|---|
| s = set() # 空集合
s = {1, 2, 'Hello, world!', True}
|
在编写 Python 代码时,请勿使用数据类型名直接作为变量,如:
字典支持的常用操作如下:
| Python |
|---|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31 | s = {1, 2, 'a'}
# 添加元素
s.add(3)
print('添加元素后:', s)
# 删除元素
s.remove('a')
print('删除元素后:', s)
# 集合取交集
print('集合取交集:', s & {2, 3, 4})
# 集合取并集
print('集合取并集:', s | {7, 8, 9})
# 集合取差集
print('集合取差集:', s - {1, 2})
# 转换为列表
print('转换为列表:', list(s))
# 循环遍历元素
print('循环遍历元素:')
for x in s:
print(' Value =', x)
# 获取集合元素个数
print('获取集合元素个数:', len(s))
# 列表去重
l = [1, 1, 2, 3, 4, 4, 4, 5, 6]
print('列表去重:', list(set(l)))
|
输出:
| Text Only |
|---|
1
2
3
4
5
6
7
8
9
10
11
12 | 添加元素后: {3, 1, 2, 'a'}
删除元素后: {3, 1, 2}
集合取交集: {2, 3}
集合取并集: {1, 2, 3, 7, 8, 9}
集合取差集: {3}
转换为列表: [3, 1, 2]
循环遍历元素:
Value = 3
Value = 1
Value = 2
获取集合元素个数: 3
列表去重: [1, 2, 3, 4, 5, 6]
|
4.5 相互嵌套
列表、字典、集合之间可以相互嵌套,实现复杂的数据结构,如:
| Python |
|---|
1
2
3
4
5
6
7
8
9
10
11
12 | data = [
{
'name' : 'Tom',
'age' : 30,
'titles': ( 'Programmer', 'Writer' )
},
{
'name' : 'Jerry',
'age' : 17,
'titles': { 'Student' }
}
]
|
而有基本数据类型、列表、元组、字典组成的复杂数据,可以通过 Python 内置的 json 库输出为 JSON 字符串,如:
| Python |
|---|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16 | import json
data = [
{
'name' : 'Tom',
'age' : 30,
'titles': ( 'Programmer', 'Writer' )
},
{
'name' : 'Jerry',
'age' : 17,
'titles': [ 'Student' ] # 注意:此处为列表
}
]
result = json.dumps(data, indent=2)
print(result)
|
输出:
| Text Only |
|---|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17 | [
{
"name": "Tom",
"age": 30,
"titles": [
"Programmer",
"Writer"
]
},
{
"name": "Jerry",
"age": 17,
"titles": [
"Student"
]
}
]
|
5. 分支处理 if-elif-else 语法
在 Python 中,使用if ... elif ... else进行分支处理,如:
| Python |
|---|
| i = 80
if i >= 90:
print('优')
elif i >= 75:
print('良')
elif i >= 60:
print('中')
else:
print('差')
|
输出:
分支处理也可以嵌套,实现更复杂的控制,如:
| Python |
|---|
| i = 42
if i % 2 == 0:
print('偶数')
if i % 3 == 0:
print('可以被 3 整除')
else:
print('奇数')
|
输出:
6. 循环处理 for 和 while 语法
在 Python 中,可以使用for ...或while ...进行循环处理。
6.1 for 循环
for 循环一般用于已知循环次数的处理,如遍历列表等,如:
| Python |
|---|
| l = ['Tom', 'Jerry', 'Lucy']
for x in l:
print(x)
|
输出:
也可以使用range(...)直接指定循环次数,如:
| Python |
|---|
| for i in range(3):
print(i)
|
输出:
也可以使用enumerate(...)对列表等进行循环,并同时获得索引,如:
| Python |
|---|
| l = [ 'a', 'b', 'c', 'd' ]
for i, c in enumerate(l):
print(f'{c} 的索引是 {i}')
|
输出:
| Text Only |
|---|
| a 的索引是 0
b 的索引是 1
c 的索引是 2
d 的索引是 3
|
6.2 while 循环
while 循环一般用于已知循环条件的处理,当条件满足时执行循环,不满足后结束循环,如:
| Python |
|---|
| i = 2
while not (i % 2 == 0 and i % 3 == 0 and i % 5 == 0):
i = i + 1
print('可同时被 2, 3, 5 整除的数字为:', i)
|
输出:
使用 while 循环需要特别注意条件的设定,避免条件永远满足产生死循环
6.3 跳过、中断循环
在循环过程中,可以使用continue语句立刻跳至下一次循环,也可以使用break语句结束整个循环,如:
| Python |
|---|
| for i in range(100):
if i < 2:
continue
if i % 2 == 0 and i % 3 == 0 and i % 5 == 0:
print('100 以内第一个可同时被 2, 3, 5 整除的数字为:', i)
break
|
输出:
| Text Only |
|---|
| 100 以内第一个可同时被 2, 3, 5 整除的数字为: 30
|
7. 函数
函数是一段可以重复利用的代码,减少编码的复杂度,如:
| Python |
|---|
1
2
3
4
5
6
7
8
9
10
11
12 | def plus(a, b):
return a + b
questions = [
[1, 2],
[4, 5],
[9, 3],
]
for x in questions:
result = plus(x[0], x[1])
print(result)
|
输出:
7.1 函数参数
在上例中,plus函数包含了a、b两个参数作为输入参数。在函数内部可以直接使用输入参数进行处理。
此外,函数参数也支持默认值。指定了默认值的参数在调用时可以不用指定参数值,如:
| Python |
|---|
| def hello(name='my friend'):
print('Hello!', name)
hello()
hello('Tom')
|
输出:
| Text Only |
|---|
| Hello! my friend
Hello! Tom
|
函数参数在调用时,也可以使用参数=值的方式进行调用,不需要按顺序严格对应,如:
| Python |
|---|
| def hello(name='my friend', message='What a day!'):
print('Hello!', name)
print(message)
hello('Tom')
hello(message='How is going', name='Jerry')
|
输出:
| Text Only |
|---|
| Hello! Tom
What a day!
Hello! Jerry
How is going
|
7.2 函数返回值
return 语句用于返回函数返回值,除了输出单个值外,函数也可以一次返回多个值,如:
| Python |
|---|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15 | def check_score(score):
if score >= 90:
return True, '优'
elif score >= 75:
return True, '良'
elif score >= 60:
return True, '中'
else:
return False, '差'
result = check_score(90)
print('使用单个变量接收:', result)
is_ok, result = check_score(80)
print('使用对应数量变量接收:', is_ok, result)
|
输出:
| Text Only |
|---|
| 使用单个变量接收: (True, '优')
使用对应数量变量接收: True 良
|
8. 导入模块 import 语句
在较为复杂的项目中,往往需要将代码布置在多个不同的脚本中,方便维护和管理。
当需要在脚本之间调用代码时,需要使用import语句来导入。
| 被导入脚本位置 |
导入方式 |
| 同目录下的 Python 脚本 |
import {脚本名} |
| 下层目录下的 Python 脚本 |
import {目录名}.{脚本名} |
| 仅导入部分内容 |
from {脚本名} import {对象 1}, {对象 2}, ... |
此外,对于名称较长的外部脚本,可以使用import xxx as yyy来取别名,如:
| Python |
|---|
| # a.py 脚本
def hello():
print('Hello from a.py')
def hello2():
print('Hello2 from a.py')
def hello3():
print('Hello3 from a.py')
|
| Python |
|---|
| # sub_folder/b.py 脚本
def hello():
print('Hello from sub_folder/b.py')
|
| Python |
|---|
| # main.py 脚本
import a # 导入 a
import sub_folder.b as b # 导入 sub_folder/b,并取别名为 b
from a import hello2, hello3 # 从 a 中导入 hello2, hello3
a.hello()
b.hello()
hello2()
hello3()
|
输出:
| Text Only |
|---|
| Hello from a.py
Hello from sub_folder/b.py
Hello2 from a.py
Hello3 from a.py
|
此处有关 import 的描述仅为最简单常用的部分,有关完整、详细 import 介绍请参考专业教程
8.1 DataFlux Func 中的脚本
由于 DataFlux Func 本身对脚本管理存在特殊机制。DataFlux Func 中脚本在系统中并非以文件形式存在,而是保存在数据库中。因此,在 DataFlux Func 中导入其他脚本与原版 Python 存在一些区别。
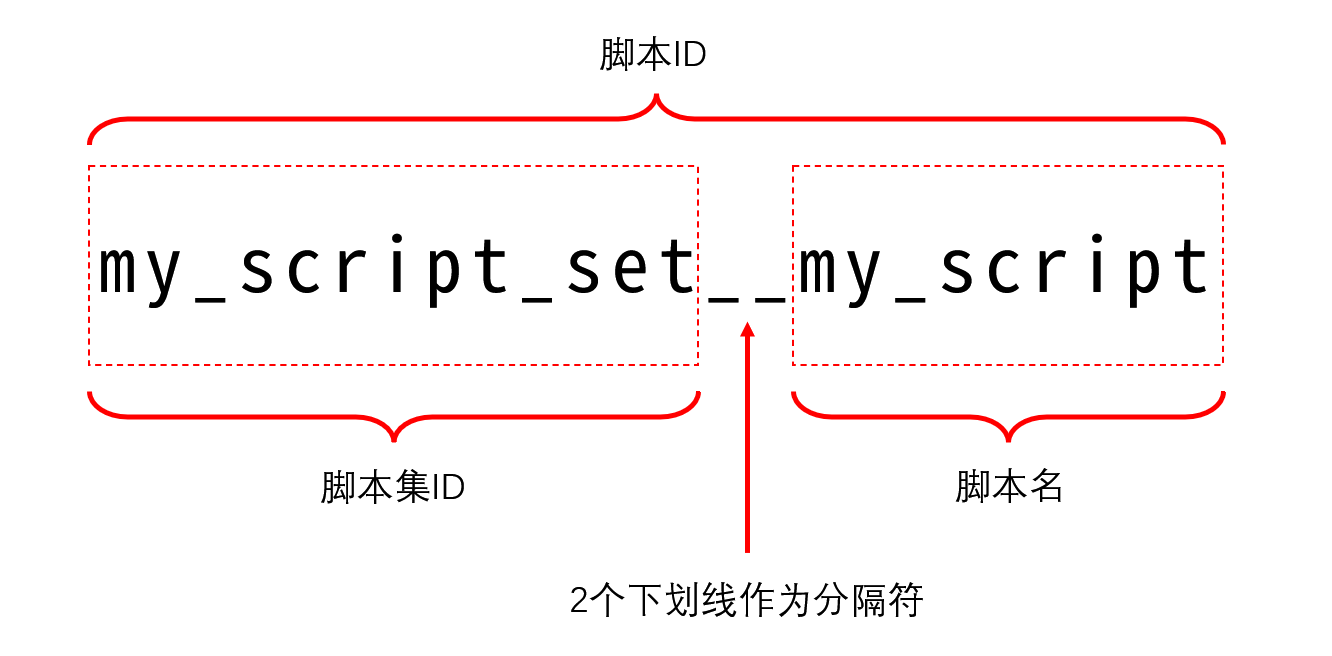
在 DataFlux Func 中,以两层方式组织 Python 脚本,第一层为「脚本集」,第二层为「脚本」。脚本集仅仅是脚本的集合,并非「文件夹」。
脚本集与脚本各自存在 ID 且具有关联性,在某个脚本集下的脚本,脚本 ID 一定是{所属脚本集 ID}__{脚本名}(中间为 2 个下划线),如图所示:
8.2 在 DataFlux Func 中导入脚本
假设存在如下脚本集和脚本:
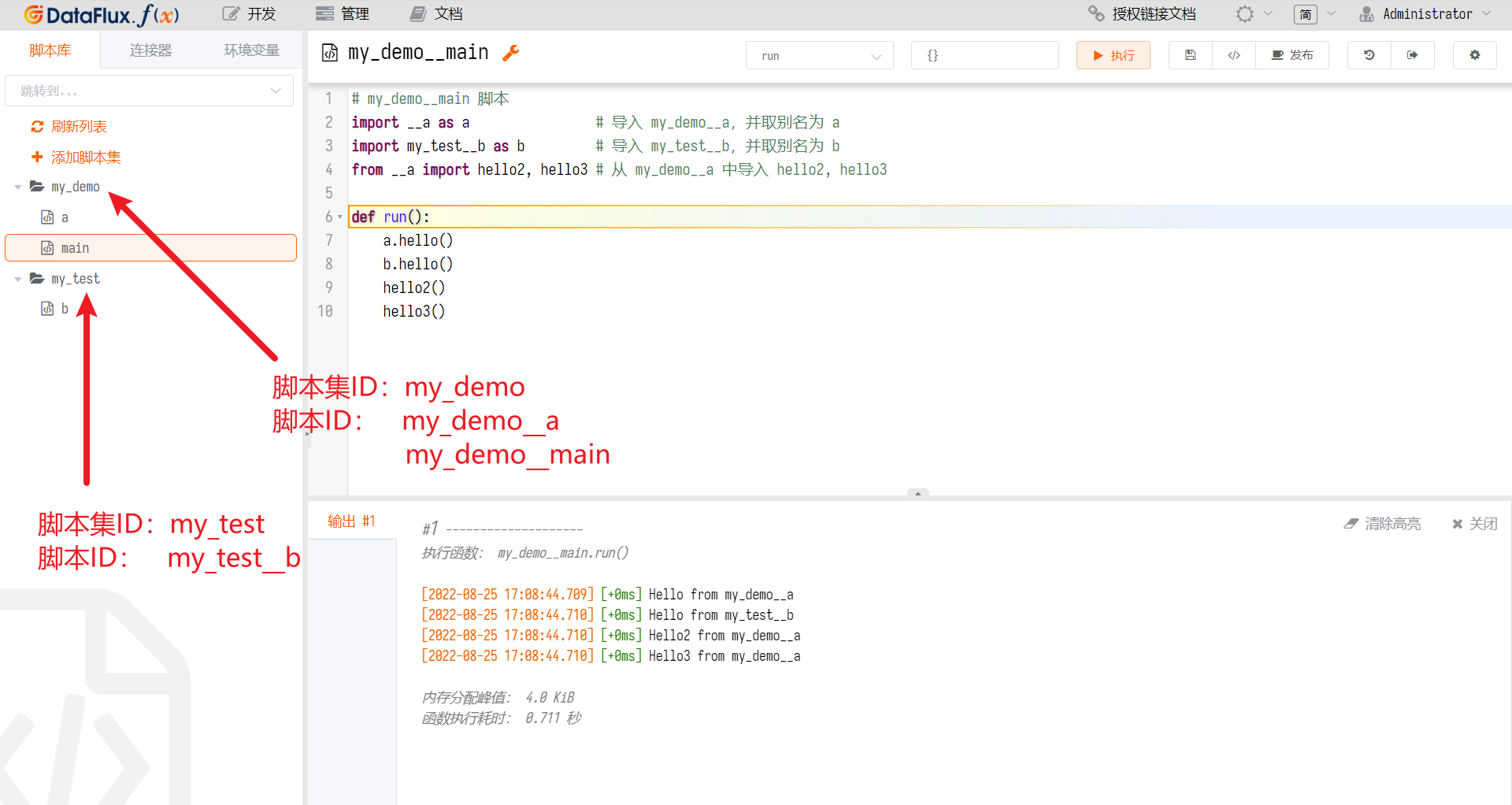
那么,导入方式如下:
| 被导入脚本位置 |
导入方式 |
| 同脚本集下的 Python 脚本 |
import __{脚本名}
或 import {脚本 ID} |
| 其他脚本集下的 Python 脚本 |
import {脚本 ID} |
| 仅导入部分内容 |
from {脚本名} import {对象 1}, {对象 2}, ... |
对于同脚本集下的 Python 脚本,推荐使用 import __{脚本名} 方式导入,这样在克隆整个脚本集后能够保证引用路径依然正确
9. 代码注释
在脚本中添加注释是个良好的习惯。
注释可以用来解释所写的代码,或者对特殊处理进行备注,以便其他人或者自己回头查看代码时,可以快速了解代码的处理细节。
具体注释的详细程度,可以根据实际项目、代码、处理复杂度,在合理范围内选择。
注释示例如下:
| Python |
|---|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17 | # 日期:2022-01-01
# 作者:张三
#
# 查找一定范围内,第一个可同时被 2, 3, 5 整除的数字
MAX_INT = 100 # 查找范围最大值
for i in range(MAX_INT):
# 忽略小于 2 的数字
if i < 2:
continue
# 核心处理
if i % 2 == 0 and i % 3 == 0 and i % 5 == 0:
print('100 以内第一个可同时被 2, 3, 5 整除的数字为:', i)
# 只需要找到第一个数字即可
break
|
10. 面向对象编程
上文中的例子中,都是基于面向过程式的编程,代码完全由函数组成。
Python 是多范式的编程语言,它除了可以完全以面向过程式进行编写外,也可以在其中增加面向对象的技术,使得代码更加简洁易于维护。
对于简单的处理,面向过程式如果能够处理好的话,没有必要强行用面向对象的技术。此处仅为 Python 面向对象编程开发的简单演示
10.1 类和继承
「类」指的是具有共同或类似功能、数据的对象集合,一个类是什么主要看每个人的具体实现思路,没有严格的统一规则。
类和类之间可以存在继承关系,被继承的类称为「父类」,继承者类称为「子类」。继承关系同样根据每个人的具体实现思路进行编写,没有严格统一的规则。
一般而言:
- 父类中会编写一些所有子类都具有的共同方法,继承父类的子类不必重复编写,即可自动获得父类的所有方法
- 子类中可以继续编写更多方法,这些方法只能在子类对象上调用
- 如果父类的方法在子类中不适用,子类也可以重新编写同名方法,来改变此方法在子类对象中的处理
10.2 典型示例
假设存在一个「学校人事管理系统」,主要业务对象如下:
| 人员 |
说明 |
| 教师 |
有姓名,有门禁卡,进行教学活动 |
| 学生 |
有姓名,有门禁卡,进行学习活动 |
可以看到,不同人员都具有门禁卡,但可以进行的参观活动不同。那么,在具体代码实现上,有关门禁卡可以统一处理,而进行的活动需要分别处理。
示例代码如下:
| Python |
|---|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65 | class User(object):
'''
用户基础类
'''
def __init__(self, name, id_card_no):
'''
用户初始化方法
需要传入门姓名、禁卡号
'''
self.name = name
self.id_card_no = id_card_no
def show_id_card(self):
'''
出示门禁卡
'''
print(f'{self.name}的门禁卡号为:{self.id_card_no}')
def do_activity(self):
'''
进行活动
由于不同类型的用户进行的活动不同,此处没有具体实现,直接抛出错误
'''
raise NotImplemented()
class Teacher(User):
'''
教师类
继承用户基础类
'''
# 此处不需要重复编写有关门禁卡的代码
def do_activity(self):
'''
进行教学活动
与父类 User 中的 do_activity 方法同名,会覆盖父类的同名方法
在对教师对象调用 do_activity 时,实际执行的是本方法
'''
print(f'{self.name}老师开始为学生上课')
class Student(User):
'''
学生类
继承用户基础类
'''
# 此处不需要重复编写有关门禁卡的代码
def do_activity(self):
'''
进行学习活动
与父类 User 中的 do_activity 方法同名,会覆盖父类的同名方法
在对学生对象调用 do_activity 时,实际执行的是本方法
'''
print(f'{self.name}同学已经进入教室开始学习')
zhang_hua = Teacher(name='张华', id_card_no='T-001') # 实例化教师类
li_ming = Student(name='李明', id_card_no='S-088') # 实例化学生类
# 将所有人放入同一个列表中,依次执行
users = [ zhang_hua, li_ming ]
for u in users:
u.show_id_card()
u.do_activity()
|
输出:
| Text Only |
|---|
| 张华的门禁卡号为:T-001
张华老师开始为学生上课
李明的门禁卡号为:S-088
李明同学已经进入教室开始学习
|
11. 错误处理
对于一些不确定是否会有问题的地方(如调用其他系统接口等),代码运行过程可能出错导致整个程序崩溃,如:
| Python |
|---|
| def get_data():
'''
一个会产生除零错误的函数
'''
return 100 / 0
data = get_data()
print(f'获得的数据为{data}')
|
输出:
| Text Only |
|---|
| Traceback (most recent call last):
File "python-study.py", line 7, in <module>
data = get_data()
File "python-study.py", line 5, in get_data
return 100 / 0
ZeroDivisionError: division by zero
|
此时,我们需要对有可能出现问题的代码使用进行额外的处理。
由于程序崩溃本身也会输出有用的错误信息,因此并不是必须要对每一段代码都进行错误处理。此处仅为 Python 错误处理的简单演示
11.1 错误处理 try-except 语法
可以使用try ... except来对可能发生的错误进行处理,如:
| Python |
|---|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15 | def get_data():
'''
一个会产生除零错误的函数
'''
return 100 / 0
try:
# 可能存在问题的代码块
data = get_data()
print(f'获得的数据为{data}')
except Exception as e:
# 发生错误后,进行处理的代码块
print('无法获取数据')
print(f'错误信息:{e}')
|
输出:
| Text Only |
|---|
| 无法获取数据
错误信息:division by zero
|
11.2 抛出错误 raise 语句
当我们在自己编写代码时,如遇到不合规范的输入参数,也可以主动抛出错误,如:
| Python |
|---|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18 | def plus(a, b):
if a is None or b is None:
raise Exception('a 或 b 为空,无法相加')
return a + b
# 尝试将 100 和 None 相加
try:
result = plus(100, None)
print(result)
except Exception as e:
print(e)
# 尝试将 100 和 200 相加
try:
result = plus(100, 200)
print(result)
except Exception as e:
print(e)
|
输出: